March 2026
How the Accrual platform works
A technical look at how an AI agent prepares tax returns
There is no shortage of AI products that can summarize a document or answer a question about a PDF. Preparing a tax return is a fundamentally different problem. It requires reading dozens of document types simultaneously, resolving conflicts and ambiguities between them, mapping thousands of individual data points into structured worksheet fields, and producing output where every value is traceable to a specific source. This article explains how Accrual is architected specifically for accounting firms — and why the design decisions behind it preserve the trust, transparency, and judgment the profession depends on.
The core architecture: preparation, not calculation
The most important design decision in Accrual is what the AI agent does — and what it deliberately does not do.
Accrual's agent is a preparation engine. It reads client documents, determines which tax engine worksheets need to be completed, maps extracted data into the correct fields, and produces a fully cited draft return. It does not calculate tax liability, generate government forms, or file returns. Those operations belong to your tax engine, which remains the authoritative system for all calculations, diagnostics, and filing.
This division is intentional. Tax calculation involves thousands of interacting rules, phase-outs, limitations, and state-specific provisions that change annually. A purpose-built calculation engine, maintained by dedicated tax engineering teams, handles this correctly. A language model should not. The strength of a language model lies in understanding unstructured information, reasoning about how data maps to tax concepts, and producing structured output — exactly the skills required for preparation. The strength of a tax engine lies in deterministic, rule-based computation. Accrual uses each where it excels.
The practical result: every worksheet you see in Accrual is an input to your tax engine. When you export, the tax engine calculates the return, runs diagnostics, and generates the actual 1040 and schedules. If the calculation logic changes — a new phase-out threshold, an updated depreciation rule — the calculation updates automatically on the next export without requiring any changes to Accrual.
How we approach accuracy and reduce hallucination
Language models can generate plausible-sounding output that isn't grounded in actual source data. In tax preparation, this failure mode is unacceptable — a hallucinated number in a worksheet field creates an incorrect return. Our approach to this problem has several layers.
Every field cites its source. When the agent populates a worksheet field, it records exactly which document, which page, and which value it used. In the review interface, clicking any citation navigates directly to the highlighted bounding box in the original document – a visual link to the specific location on the specific page where the data appears. For calculated fields that aggregate information from multiple sources (a Schedule C that totals expenses from a client-provided spreadsheet, for example), each contributing value is individually cited.
The agent generates preparer notes for areas of uncertainty. Rather than silently guessing, the agent flags situations where information is ambiguous, missing, or unusual. These notes are actionable — they describe what was found, what seems atypical, and what the reviewer should investigate. The goal is to make the agent's reasoning transparent: you can trace any value in the return back to a source document, and any uncertainty is surfaced before you encounter it during review.
We don't build our own language model. Accrual benchmarks continuously across frontier models from OpenAI, Anthropic, and Google, selecting the best-performing model for each task based on our internal accuracy evaluations. When a new model release improves extraction accuracy or reasoning quality, we can adopt it immediately. Our proprietary layer is the expert instructions, prompt architecture, and tax-specific orchestration that sit on top of these foundation models — developed with internal CPAs and refined with every firm and every tax season. The system gets measurably better each year.
The document processing pipeline
Tax preparation starts with documents, and real-world client documents are messy. Clients upload combined PDFs that are hundreds of pages long. They send phone photos of handwritten expense logs. They forward password-protected brokerage statements. They email Excel spreadsheets with no consistent formatting. An effective system needs to handle all of this — not just the clean, standard government forms.
Pre-processing: making documents machine-readable
Before the agent begins working with documents, Accrual runs every uploaded file through a normalization pipeline. Combined PDFs — sometimes hundreds or thousands of pages containing dozens of individual documents — are automatically split into separate virtual documents, each named by its detected content (e.g., "2024 K-1 for Chris Wolff from KKR Private Equity"). Scanned pages are rotated to the correct orientation. Password-protected files are unlocked once and persisted securely. ZIP archives are expanded. Less common formats are converted to processable representations.
Accrual supports all major file types practitioners encounter: PDFs, Word and Excel files, CSVs, all common image formats, and email files. The goal is simple — ensure the agent can work with everything a human preparer would review, regardless of how it arrives.
Contextual processing, not document-by-document extraction
The traditional approach to tax document processing — and the approach used by most extraction tools — is to process each document in isolation. The system looks at a W-2, extracts the fields it recognizes against a predefined template, and moves on to the next document. This works reasonably well for clean, standard government forms. It fails in two important ways: it can't handle documents that don't match a known template, and it can't use information from one document to interpret or validate another.
Accrual works fundamentally differently. Rather than extracting data from documents one at a time against fixed schemas, the agent considers the entire document set holistically — the same way a human preparer would spread everything across their desk and work with full context.
This distinction matters in practice. An SSN that's partially illegible on a scanned W-2 can be confirmed by cross-referencing the same SSN on a 1099 or the client's prior-year return. An address that differs between two documents can be resolved by checking which one is more recent or by referencing the client profile. An email exchange between the client and their accountant might explain why a particular 1099 should be excluded from the return, or provide context that a deposit shown on a bank statement was a non-taxable reimbursement. A binder response might clarify that the client made an IRA contribution that doesn't appear on any document yet.
None of this is possible when documents are processed in isolation. It requires the agent to hold the full context of the client's situation — documents, emails, binder responses, client profile, prior-year return — and reason across all of it simultaneously.
Accrual does not use static extraction schemas. Every document is processed in context, and the agent can take multiple passes at the same document to extract additional information as the return takes shape and the needed data points become clearer. A document that initially yields basic income figures might be revisited later in the process to extract state withholding detail or cost basis information that becomes relevant as other worksheets are populated.
All processed data generates visual bounding boxes that link each value to its precise location in the source document. Whether the value is a single field (Box 1 wages from a W-2) or a calculated aggregate (total farm expenses from a client-provided spreadsheet tallied into a Schedule F), the citation chain is complete and visual. In Armanino's pilot, one in five document types processed by Accrual was not supported by the incumbent extraction tool — precisely because those tools relied on fixed templates for a limited set of forms.
K-1 processing: a case study in complexity
Schedule K-1s illustrate why contextual, multi-pass processing matters. A K-1 from a partnership or S-corporation contains standard box values, but the real complexity lives in the footnotes — supplemental schedules that modify, reclassify, or add detail to the standard entries. Box 20 code AH might reference a footnote containing Section 199A QBI information. Box 13 code W might point to a supplemental schedule breaking out separately stated deductions. These footnotes aren't standardized — every partnership produces them differently, and interpreting them correctly often requires cross-referencing multiple pages within the same K-1 package as well as the client's other K-1s to understand activity classifications.
Accrual processes K-1 footnotes as first-class data, cross-referencing supplemental schedules against the standard boxes, resolving references between them, and mapping the combined information into the appropriate tax engine worksheets. The system tracks K-1 activities across all of a client's partnerships and preserves activity numbering to match prior-year elections — essential for maintaining consistency with the preparer's existing classifications.
Tax preparation: plan, execute, iterate
Return generation isn't a single-pass extraction. The agent follows a structured process: analyze all available information, create a tax plan, then execute that plan across worksheets — iterating as more information becomes available.
The tax plan
When you create a return, the agent first analyzes the complete set of available inputs: the client profile, all uploaded files, binder responses, matched inbox emails, and the imported pro-forma return from your tax engine. From this, it constructs a tax plan to determine which worksheets need to be completed, which state returns are required, how K-1 activities should be classified, and how prior-year elections should carry forward.
The pro-forma return is particularly important. It provides the agent with a prior-year blueprint: which worksheets existed, which activities were tracked, what elections were made. This context significantly improves accuracy, especially for complex returns where continuity between tax years matters.
Parallel execution
The agent doesn't process worksheets sequentially. It orchestrates many workflows in parallel, so even returns with 100+ client files and 200+ worksheets complete in a reasonable timeframe — typically 10 to 30 minutes regardless of complexity. Returns with dozens of K-1s, multiple state filings, and extensive brokerage activity are processed in a single coordinated run rather than requiring the agent to revisit work as new worksheets interact.
Incremental updates
Tax preparation is rarely a single event. Clients send documents in waves, for example, W-2s in February, K-1s in March, a corrected 1099 in April. Accrual's checkpoint system handles this naturally. When new information arrives — a new file upload, a binder response, a matched email — the system presents the incremental changes as a checkpoint rather than regenerating the entire return. You review what changed, accept or reject the updates, and the return evolves without losing the work already done.
The review experience: more than a chat interface
A common pattern in AI products is to wrap a language model in a conversational interface and call it done. Accrual takes a fundamentally different approach: the product is a purpose-built review environment for accountants, with the AI agent as the engine underneath.
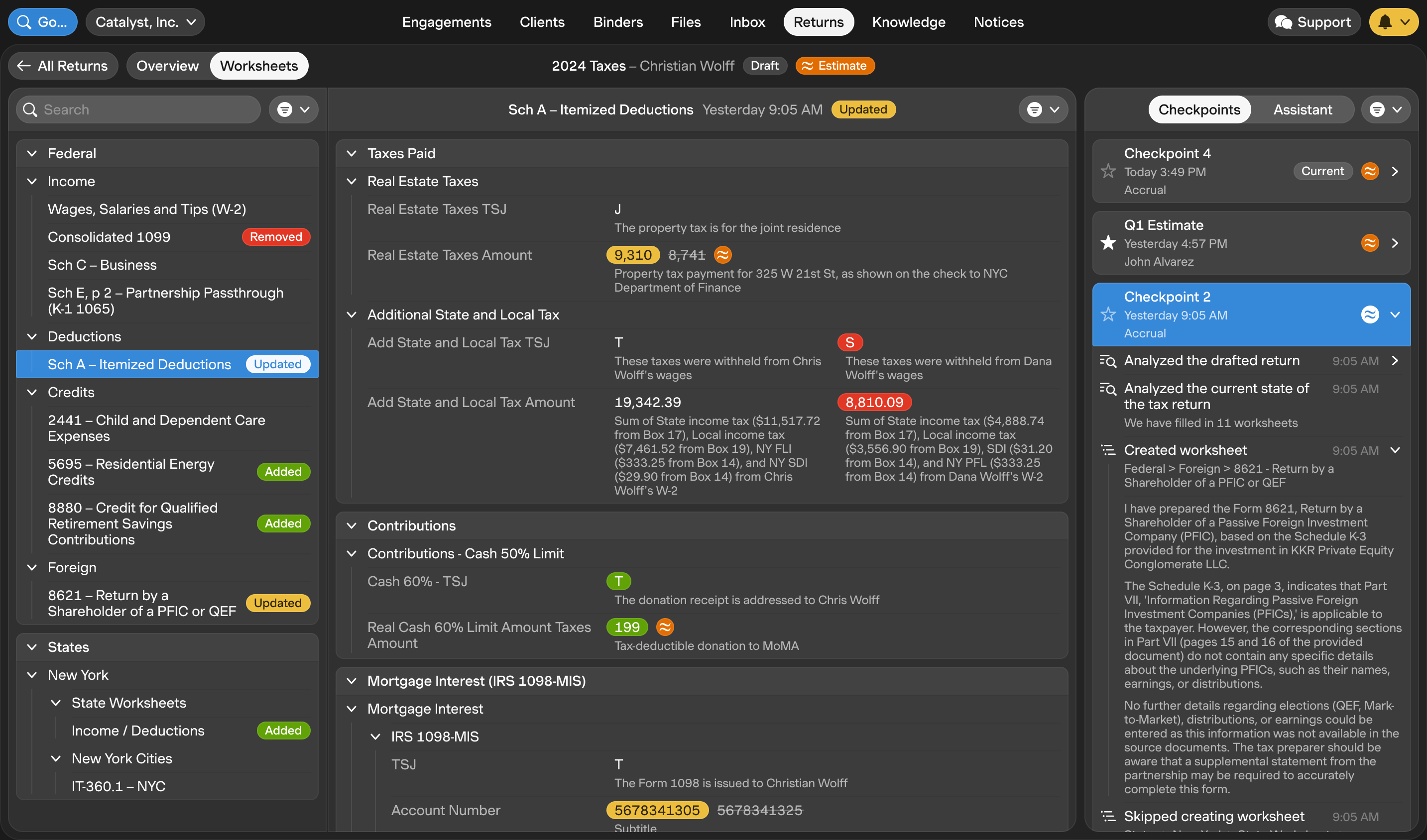
Checkpoints: version control for tax returns
In software engineering, teams use a system called “version control” to track every change made to a codebase. When a developer modifies a file, the system records exactly what changed — which lines were added, removed, or modified — and preserves the entire history so you can see who changed what, when, and why. If something breaks, you can look at the precise change that caused it. If you need to understand how a piece of code evolved over six months, you can step through every version. The key concept is the "diff", a side-by-side comparison that highlights exactly what's different between two versions, so a reviewer doesn't have to re-read the entire file to understand what changed.
Tax returns have the same problem that version control solves. A return with 150 worksheets and thousands of fields evolves over weeks, then new documents arrive, the preparer makes corrections, the agent resolves issues, someone edits a value directly in the tax engine. Without a structured change history, reviewers face an impossible question: what changed since the last time I looked at this? In traditional workflows, the answer is usually "re-review everything" or "trust that someone kept notes." Neither scales.
Accrual applies version control to tax preparation through checkpoints. Every change the agent makes after the initial draft is captured as a checkpoint — a visual diff showing exactly which worksheet fields were updated, from what values, to what values, with the source of the change identified.
Concretely: if the agent updates the Schedule A after a client uploads a corrected property tax statement, the checkpoint shows you that one field changed (real estate taxes paid), what the previous value was ($8,741), what the new value is ($9,310), and which document triggered the update. You don't re-review the entire Schedule A. You review the one thing that changed.
This matters most in three scenarios:
Late-arriving documents. A K-1 arrives in March for a return that was already drafted in February. The agent processes the new K-1 and presents a checkpoint showing every worksheet field that was added or modified as a result, potentially across multiple schedules (Schedule E, Form 8960 Net Investment Income Tax, state worksheets). You review the incremental impact of that one document, not the entire return.
Agent issue resolution. When you instruct the agent to reclassify a K-1 activity from passive to non-passive, the change can cascade across a dozen linked worksheets. The checkpoint captures every downstream modification in a single reviewable view, so you can confirm the full scope of the change before accepting it.
Tax engine re-sync. If a partner makes adjustments directly in the tax engine, you can reimport those changes into Accrual. The checkpoint shows exactly what the tax engine version contains that differs from Accrual's version — field by field — so you can accept the changes with full visibility rather than hoping the two systems are still aligned.
Checkpoints are triggered by these three events: new client information (files, binder responses, matched emails), agent instructions (when a preparer asks the agent to fix an issue or add a worksheet), and tax engine reimport. In every case, you preview the proposed changes line by line before accepting them.
The checkpoint history is browsable. You can step back through previous versions to see how a return evolved over the entire season — when each worksheet was created, what changed at each step, and what triggered the change. This provides a complete, auditable history of the preparation process that didn't exist before: not just who signed off on the return, but the precise sequence of changes that produced it.
Continuous improvement
Accrual's architecture is designed to improve with each tax season. The underlying language models advance — when OpenAI, Anthropic, or Google releases a model with better extraction accuracy or stronger reasoning, our benchmarking infrastructure identifies the improvement and we can adopt it for the relevant tasks. Our tax-specific instruction layer, developed with in-house CPAs, is continuously refined and backtested against real returns completed by practitioners. And the orchestration engine — how the agent plans, executes, and iterates on returns — incorporates lessons from each firm's patterns and feedback.
The result is a system that gets measurably better between seasons: higher accuracy, faster processing, and a review experience that continues to close the gap between "draft return" and "final return."
For a deeper look at how Accrual works with your specific client data, request access to try the platform.